v2+ Details
0.3.2 - Working Draft to present the concept ideas (FO)
v2+ Details
0.3.2 - Working Draft to present the concept ideas (FO)
v2+ Details - Local Development build (v0.3.2). See the Directory of published versions
Data exchange requirements can be aligned with three different axes that take effect at different points in time:
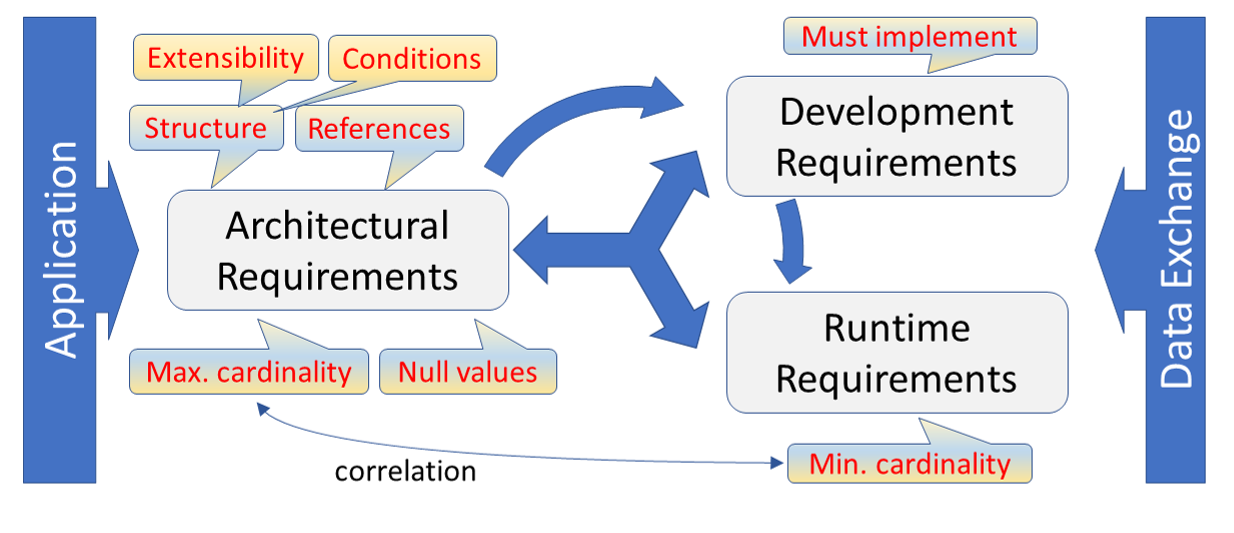
The different aspects are explained following.
The aspects dealing with architecture are meant to be realized before any detail of an interface is implemented. Without this preparation interfaces won’t be possible at all. For example, if an application has to deal with patients, that should have a name in particular, the name of a patient must be handled in some way. At least, there must be some kind of storage area to store the details of a name. Here it does not matter, what the details are, the generic part is sufficient for the moment. What counts is the ability to store that information and to retrieve it again - as is or as it has been provided.
If it becomes important to separate between the given name and the family name of a patient, for example to print them separately on a form, then this distinction must be handled. In the sense of architectural aspects, this distinction will become detailed substructures for a name. In other words, due to the drawing/figure above, these aspects (given and familiy name) will form subnodes to the parent node (name) that itself is a subnode to another parent (patient).
That way a hierarchy can be formed that represent all details in a reasonable and meaningful way.
An important aspect when creating this simple hierarchy is the use of repetitions. Some nodes will be used to represent multiple occurances of the same information. For example, a patient may have several names, either in parallel or subsequently. That kind of repetition must be managed somehow as well. Using the name as an example, it makes a difference whether the application can handle different types of names only, eg. name at birth and current name, as separate entities, or as real repetitions with additional information (metadata) that informs about the difference, eg. as a name or usage type. Another good means to assist in management would be the use of a date range to indicate current and former old names. It is up to the application how this is done. However, either means will then be added as specific subnodes to the same parent.
The latter architectural requirement is commonly called maximum cardinality. In most cases it is not restricted to a real maximum. For specific realizations, mostly introduced by UI requirements, this can be limited to a small number, e.g. one-digit numeric.
However, not everything will be stored in form of a single hierarchy. Using relational databases, specific subbranches are separated into distinct tables and linked to each other. For example, diagnosis information (one branch) will be related to patients (another branch). Both will become separate tables with appropriate links by storing foreign keys.
The way this separation is done is commonly controlled by entity-relationship-diagrams, or more generally by (domain) information models. Both influence the basic requirements for developing an interface if the relations are to be pursued.
The aforementioned requirements and their realization within an architecture specify the basic requirements for data exchange. For example, if a field is provided, then it is generally possible to exchange the contained data. But if the occurence of the data is necessary for other reasons, e.g. to generate a primary key, or to store the information at all, e.g. a diagnosis without a diagnosis code is useless, it forms a minimum requirement in form of minimum cardinality which is normally set to one (“1”) then. A minimum cardinality of zero (“0”) is used if the capability is provided, but no information is a valid option.
Once the foundation as previously mentioned is provided, it depends on the interface capabilities whether this data is taken and appropriately communicated. In other words, in most cases it depends on the strategy of the company or company owner to make specific data available via an interface or not.
If the general capability is provided by an application some code must be written to take the data from its storage location and to place it in a message/document of vice-versa. This aspect can be named as “supports”: An interface supports a specific data element. (Or from the perspective of a requirements: An interface must support a specific data element so that the application can deal with it.)
In order to manage this support appropriately, the structure of the data element is important, if this element is not managed in a general way.
For v2+, this development aspect is called “implement” because a developer has to write - implement - source code.
Accessing information in a data exchange record may result in errors if the information is not provided. So care must be taken therefore to deal with absent information. Hence it is to a running interface to determine whether information is present or not, and to take appropriate action.
Each conformance construct can clearly be associated with one of the three axes. That also denotes the importance of the architecture of a system for data exchange, and the value of an overarching (domain) information model for interoperable systems.