v2+ Details
0.3.2 - Working Draft to present the concept ideas (FO)
v2+ Details
0.3.2 - Working Draft to present the concept ideas (FO)
v2+ Details - Local Development build (v0.3.2). See the Directory of published versions
Codesystems are a convenient way to shortcut and simplify data entry and maintenance: Presumably complex information is maintained and stored behing and by using placeholders - codes (with additional attributes). The intent is to have a common understanding of what each code means. Therefore, a code is always to be combined with the information from which codesystem including it’s version it is derived.
This page is intended to provide some background information on the use of codes and codesystems. Therefore, we are concentrating on the right part of the following diagram:
Maintaining vocabulary requires some metadata that is provided in form of attributes.
What are necessary attributes for codesystems?
What are necessary attributes for codes?
Codesystem is a generic term for different types of vocabulary:
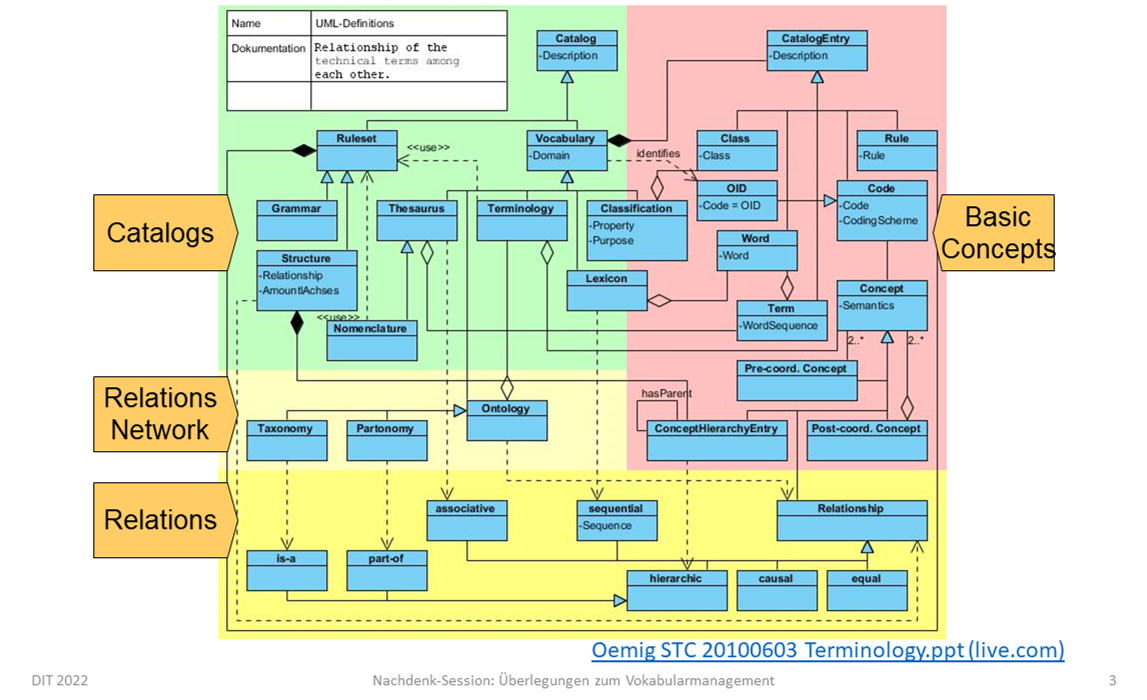
The different aspects will be explained following.
TODO
TODO
TODO
TODO
TODO
A table is an outdated view to a list of values that should be used as codes. This perspective ignores all relevant aspects for maintaining vocabulary. And it is an unclear of the union of concept domains, value sets and codesystems. Therefore, this notion shall not be used anymore. Instead the correct concepts should be used.
When creating codesystems several aspects must be considered:
An important question is in which way the code is used:
A common practice is to select an alphabetic abbreviation for the coded information because it is easier to remember for implementers or to identify its meaning. Another practice is to use alphabetic representations that can be used for sorting - in case the data is stored in a database and should be retrieved by SQL statements in an appropriate order. A third way of using and creating codes is by adding (appending) characters to the end in order to establish a hierarchy.
These things are common for codesystems that are classifications. And the codes do not represent single/atomic concepts.
TODO
Another common behavior for codesystems is to have a code for “unknown”, i.e. that represents that information is not provided. In some cases, this can be further detailed to distinguish different reasons for the absence, eg. unconciousness of the patient or masked information (for security reasons).
Information about the absence of data is a codesystem in itself, and therefore it is not recommended to add codes for “unknown”. On the one hand, “unknown” destroys a codesystem from a semantical perspective, on the other the same could be realized by combining this requirement when using value sets.
In the same category falls the information that data is available, but not directly represented by one of the other codes. aGAIN; this requirement can be realized by using value sets.
Another question is how to deal with codes that should not be used anymore, or are invalid? Should those be deleted? The answer is a clear NO, because the deletion of codes violates a clean versioning with regard to semantics. (Such a change would force the development and release of a new codesystem with all the accompanying consequences.) Instead, each entry should have a status attribute that designates whether the code is active or not.
The (sub)set of codes that are to be used with implementations or data exchange are determined by value sets.
Combined with the previous question is: how to deal with coded information that is deprecated, but now to be reactivated again? Given the distinction between codes and concepts, the answer is the same: Codes are unique, and it is impossible to introduce a “new code”. For concepts it would be possible to create a new concept, but two different concepts are not allowed to have the same semantic definition - commonly known as fully specified name. Hence, both cases argue in favor of reactivating deprecated codes with a new version.
Quite a lot of codesystems are going to provide additional information with the codes. For example, a ZIP code could have an information about the federal state it belongs to. If a codesystem is provided in form of a table, then it is easy to add further columns each representing one aspect. Because such an addition is specific to the codesystem, an attribute-value approach is a generic way to manage that. When querying/filtering data, such an attribute is an ideal parameter. It can also be used for generating a complex extension for a value set.
Jim Cimino has worked on vocabulary maintenance and published some guidance on to use it:
Until further explanation is added here, the reader is defered to:
James.J. Cimino, M.D.: Desiderata for Controlled Medical Vocabularies in the Twenty-First Century Methods Inf Med. Author manuscript; available in PMC 2012 Aug 10. Published in final edited form as: Methods Inf Med. 1998 Nov; 37(4-5): 394–403. PMCID: PMC3415631, NIHMSID: NIHMS396702, PMID: 9865037