v2+ Details
0.3.2 - Working Draft to present the concept ideas (FO)
v2+ Details
0.3.2 - Working Draft to present the concept ideas (FO)
v2+ Details - Local Development build (v0.3.2). See the Directory of published versions
CAVEAT/DISCLAIMER: This page is not intended to represent and explain what is currently done in one of the standards. It should provide explanations for quite a lot of terms in an abstract way. Therefore it takes one term, and examines it’s meaning and demonstrates it’s essentials using an information model. Therefore, all those models are reduced to what is necessary to understand the explanation. This may lead to not show details that will play a role in the ultimate end.
Also, this page does not consider different types of vocabularies. This will be done on a separate page.
Ideally, all individual concepts (explained later) can (at the end) be aggregated into an overarching concept model. But this is still an open issue.
Vocabulary Management is necessary to work with coded information. In different data exchange standards this is realized in different ways, attaching the details to different artefacts, that represent and hold the coded information:
This page is intended to summarize the necessary details from what we have learned in the past from the above-mentioned standards. As can be seen, none of them is currently able to fulfill all the requirements in a clear and unambiguous way.
The next sections are used to explain the details. But within each subsection, the provided models do only take care and mention the aspects that are relevant for this individual topic. The resulting task - and challenge - is to combine all of those into a single representation (model) that can be implemented and used further on.
Following UML class diagrams are used to provide the models. In the resulting technical representation it may not be necessary to have all classes represented as - in FHIR one would say - resources.
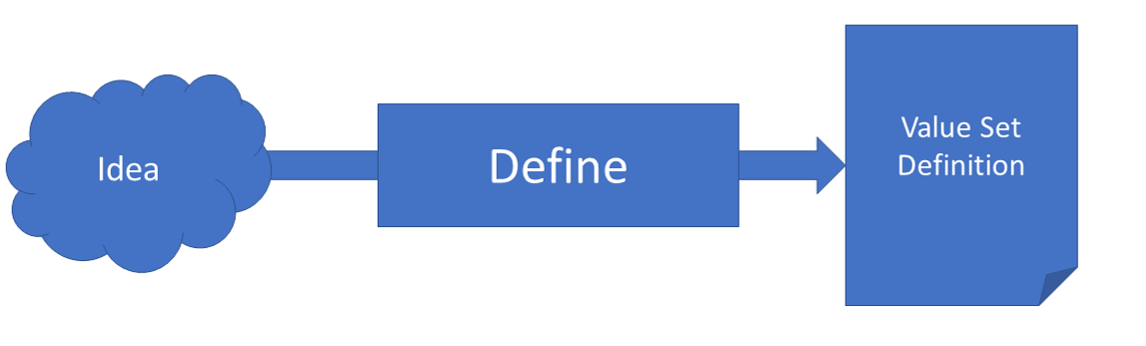
Terms: Different people like and use different terms - for probably the same or different concepts. Here the term “value set” is only used as an abstract concept that can and will not be established. Instead, this page argues on favor separating it into different concepts that are labeled “value set definition” and “value set expansion” - in different forms. As such, a value set definition may not be treated as a “set of values” as the name may introduce. But hopefully it helps to understand the notion and idea behind them. Ultimately, it ends in a set of concept definitions, that in FHIR are all implied by the ValueSet Resource: terminology2.html
This page should summaraíze and explain all concepts that are relevant when dealing with coded information. That should help with creating a vocabulary model for v2+ that is not provided here.
This page can ofcourse be further enhanced with already existing definitions and other explanations. Therefore it is concentrating on small UML models.
Such an element conveying coded information has two essential relationships: On the one hand, it has a reference to some kind of concept domain, that roughly specifies the semantics of that element, without being too specific. Which helps to ensure the correct association of values sets. On the other hand, such an element may have a binding to a construct that is commonly called value set, the details of which we will clarify later. Therefore, Value Set is an abstract concept for the moment:
In the following, coded information item is taken as the anchor to deal with. It is independent from where it occurs, and in which standard this element is used.
Coded information is bound to a value set. However, a value set is an abstract construct. Therefore, this term is only used for a package when representing it in UML to indicate that the things behind it are unclear. As a consequence, it will not be used anymore. In the previous figure it is therefore denoted as Value Set ???.
A concept domain - another synonym is vocabulary domain - should provide a high-level introduction into the purpose of a value set.
A concept domain is an abstract notion that refers to a set of related ideas (concepts) that serve to help define the meaning of a particular data element (over and above just the name of the data element). A concept domain does not directly define a particular set of concepts and is independent from a specific and explicit association to a particular vocabulary (code system or value set). As shown in the previous drawing it is an independent concept.
Some examples:
This simple list also demonstrates that concept domains may form hierarchies - (parallel) taxonomies with different axes.
UTG/THO currently provides a codesystem for this purpose: https://terminology.hl7.org/1.0.0/CodeSystem-conceptdomains.html. This is a good starting point. It must be discussed whether this is sufficient, or some further attributes are needed.
A concept domain should (shall?) be used to verify that the correct vocabulary is associated with a coded information item. For example, if a diagnosis should be provided, then several distinct codesystems may be used, and from SDO perspective they are all equal. The concept domain should prevent then, that - in our example - a procedure classification is used. A concept domain may operate as a “validator” for creating and maintaining a value set.
Coded information can be associated with multiple concept domains. The same is valid for codesystems.
A concept domain is an abstract concept and only parially used with some standards. That should not prevent us from analysing and evaluating it. Furthermore, it is not really used explicitly, and there is no means to add any kind of information to a coded information item. The “v2 tables projecct” analyzed the different tables and created/added a concept domain for all items, but without further use or deeper analysis/improvement.
Some codesystems are small and easy. But other like LOINC or SCT are huge and complex. They provide codes for different concept domains. In SCT, for example, there are different branches that belong to individual concept domains. In LOINC, as a terminology, the codes are mixed, and using the axes does not simplify the association to a concpet domain much. In essence, it will be hard to make good use of concept domains then.
Given, that different codesystems provide codes for the same concept domain result in associating multiple codesystems from a single value set definition so that a subset selection can be applied depending on the use case.
Taking the existing standards, the question comes up whether a concept domain shall be a (coded) attribute to a data element definition, value set and codesystem? Or whether it provides enough (additonal) details that a separate concept makes sense?
Currently there is little reason to maintain or persist it as a separate concept. A classification seems to be an appropriate representation form. However, within this page that explains everything abstract the concept domain will remain a separate concept.
Having said that, the idea of a classification that allows for hierarchies introduces the idea of an ontological definition so that the semantics of a concept domain is specified sufficiently and correctly.
A concept domain is a good means to specify the semantics of coded information. Ideally, all data elements, not only coded ones, shall have a proper semantic definition. The best way to do that is by using ontologies, and associating the corresponding details to the data element. From that perspective, binding to specific value sets in a generic base standard only makes sense for structural information, that is necessary to make the standard work.
Having said that, it would be good to separate vocabulary maintenance from standards specification! The v2+ v2plusmetamodel.html provides a proposal.
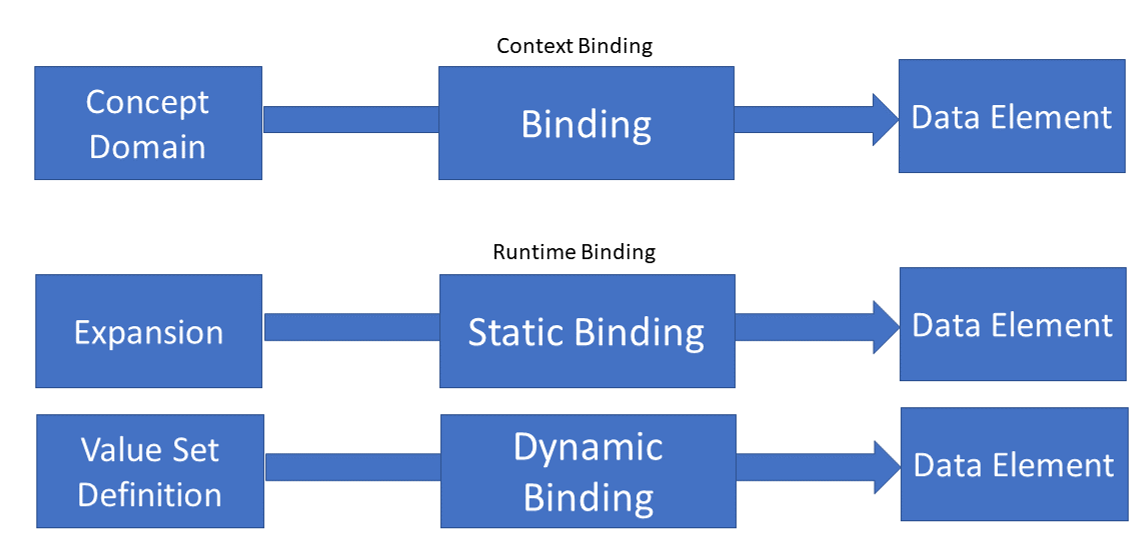
Binding is done in two different ways:
Context Binding is in principle defining the semantics of a data element and is done when a data element that should be coded is defined. This binding is done with the specification of the (base) standard. The association with a concept domain has to ensure that appropriate vocabularies are used. Currently, this is primarily done by human intuition, i.e. if a data element asks for a ZIP code that only codesystems are selected that hold this information, and not to associate an ICD catalog for example. Providing an explicit definition in form of a concept domain would support that notion in a computable way.
Because basic standards are used in manyfold ways in different environments a specific vocabulary has to be selected later when creating implementaiton guides. Ultimately, the exact binding has to be identified during runtime dynamically at site, for example when a dynamic binding is defined. This type would be called Runtime Binding.
TODO: compare with CM 6.4
What is the relationship between coded data items and codesystems? Is there a direct relationship?
In principle, a coded item can be specified by a very specific codesystem or a value set. A direct binding (to the codesytem directly) may make sense when the codesystem is strongly related to the support for a specific use case which is given fur structural coded information to make the standard work. For example, a dedicated list of status codes or other codes that are structurally/technically necessary.
But for all other vocabulary, they are created and maintained independently from an explicit data exchange standard. For HL7, different product lines exist, that may/should use the same vocabulary wherever possible. Therefore, a relationship between a coded information item and codesystems should be provided by concrete bindings using value sets.
For structural/technical voabulary, a direct binding would be possible so that a value set seems to be superfluous. The reader should be reminded, that for more specific use cases a constraint may become necessary. That cannot be realized without additional efforts because a value set must be inserted then.
In reality, the probability is high that two different vendors are implementing the provided list of codes in different ways, i.e. by selecting a subset of it:
There may be good reasons to select a subset. But when those two vendors with their selected subset of codes (both are conformant to the guidances by selecting a subset) have to interact, the not-overlapping set of codes from the two realized subsets will lead to incompatibility then if those two vendors are going to exchange their data. Compatibility can only be established (independently from the specific codesystem) if both subsets are either really identical or the sender’s set is a subset of the receiver’s.
If there is some guidance that vendors are not allowed to implement a subset, then the compatibility question is out of scope. However, it must be clear what applies.
In principle, the concept of a value set consists of - at least - two base elements that may be refined further: A value set definition and a value set expansion. Both will be explained in more details later on. The first holds in some way the details how a specific list of codes (as a triplet of code, codesystem and codesystemversion) is constructed. The second is that list of codes.
The stability of a binding of a data element to a value set can be done in two different ways:
Static binding is used to specify a detailed list of codes that shall be used without a change in the future. A dynamic binding is used if one wants to denote that the binding is somehow dependent on updating the underlying vocabulary, i.e. codesystem.
The two distinct parts of a value set named definition and expansion are the two parts to which the binding of a data element is declared. A static binding is done to an explicit value set expansion that - as a versioned element - will not change. Whereas a dynamic binding is done to the value set definition so that the current list of value (in the expansion) must be calculated (in theory) every time the set of codes is retrieved. (Of course, that can be reduced to certain triggers and appropriate caching mechanisms.)
In FHIR, we only have a (single) ValueSet resource that can be instantiated. In other words, if we want to explicitly bind a data element to a value set (instance) it must be identifiable in which way the instance is used: Is this as value set definition so that we have to generate the expansion, or the expansion? Technically, both is linking to a value set resource instance. Logically, there must be some kind of indication that must be used to differentiate between both. It can be the existance of expand elements in the instance, or a specific attribute. In both cases the $expand operation will generate a new expansion list which then will/may result in a new version of teh instance or a totally new instance itself.
In case an expansion exists already, a re-expansion may lead to a different list because an underlying codesystem may have changed in the meantime. (Ideally, the re-expansion will result in the same list.)
It appears that separate constructs as listed on this page would help to sort that out.
TODO: Also, the way how the value set resource can be profiled and instantiated is a matter of a separate examination.
Typically, there are also two ways of using value sets in combination with binding: A stable list of codes or a list that can be changed regularly. On the one hand, this separation/distinction will be used with the binding itself - as is explained above.
On the other, a value set definition can be declared as being stable so that an update of the expansion is not necessary. Typically, this is done with a dedicated list of codes. The distinction in that case is the result, that the expansion will not change even if a dynamic1 binding is done.
How to work with codes that are not part of the list? Quite often the term extensible value sets is used. In principle, the situation appears to be as follows. Both systems have implemented something that correlates to the guidance as either being a subset of it, or having some remaining elements.
Consequently, if a sending system is going to send a specific code, then it is either part of what the receiver might (should) expect as being part of the common subset on the sender side, or a subset that can be clearly specified, at least from the senders perspective (“remaining codes”). The receiver has also implemented a set of codes that he is going to accept/expect. This list is also either defined by the value set in the middle, or an extension depending on his requirements. Therefore, in reality there are no real extensions, because even “unexpected codes” from a receivers perspective can be defined in form of value sets. As such they are not extensions, just unsufficiently specified sets. Having said that, the solution to problem of extensible bindings can be transfered to proper value set declarations.
At this point, the support of a specific value set can also be addressed and solved.
TODO: next rethinking
Beside stability and extensibility the binding type is the most important aspect: Is the defined binding required for users? Or are they allowed to replace it with others?
In FHIR the binding types are as follows:
As explained above, extensibility is a different construct that does not follow the hierarchy:
example: The binding is provided but it should not be expected that the provided details are good enough or complete for real use. They are provided to convey an idea about the information. For implementation guides they must be either enhanced sufficiently or replaced.
preferred: Among different possible and provided bindings this is the preferred one. Having said that, it must be ensured that no other binding is marked as such.
required: This binding constrains the use of codes to the ones provided in the value set (definition or expansion). A required binding is not equal to a static binding to a list of codes, because an underlying codesystem change in a dynamic binding may result in a new expansion. Also, extensibility is not affected.
TODO: explain using multiple bindings with one defined as preferred!
TODO: elaborate further on the different types
Because different types may apply, this kind of information cannot be integrated into the coded information directly, but must be placed on the assocation.
Open/close is a boolean information whether it is allowed for using other codes than the ones that are defined!?
TODO: see CM
In FHIR, “required binding” is equivalent to a closed value set, i.e. no other codes are allowed to be used.
TODO
TODO
In v2.x the vocabulary binding is distinguished by HL7-defined and user-defined tables. This separation tries to declare a binding to be either mandatory for every user of the standard (HL7-defined), whereas user-defined vocabulary binding should be done by the user itself. In other words, it should become part of an implementation guide, although the term IG is not used in the standard.
From the very beginning when defining v2.x (and also implicitly from v1.0) the separation into user- and use-case-specific binding was done in form of data types which is explained later on this page.
v2+ tries to change that. At least from a vocabulary management perspective. Whether a change in data types will be possible is a separate discussion.
From a definitional perspective the primary purpose of a value set is to have a list of codes that can be used for implementation. A side-effect is to use them for validation as well. Therefore, having a simple list is sufficient, i.e. it is enough to verify that only valid codes are used.
To specify compatibility, it must be clear in which way and how the set must be supported from both sides.
To make use of value sets in implemetnations, in principle a list of triplets must be provided. A code is only uniquely identifiable when all three details are given:
In other words, a value set expansion extends to basic information for having this list - value set expansion - (with an identifier and other information about the generation like a timestamp) and a list of triplets:
Question: Can a value set expansion exist without a definition? Does it make sense?
How is a value set defined? In principle there are at least 4 different methods. And all must end in referencing to at least one codesystem:
Note: Of course, all codes should point to a codesystem where they are maintained.
The first one is self-explaining.
The second is also easy to understand. Importing codesystem are then done either in total, or by selecting a subset of this codesystem, most probably by using specific attributes of this codesystem to define a filter or just by listing them individually.
TODO: refine explanation!!!!!
The 3rd way requires some more explanation: Listing the codes by their triplets is the clean and simple way. Listing just “codes” without any reference to a codesystem is a bad idea because their semantic is not clarified then. In a hierarchic codesystem a code may be an anchor to a set of (more specific) codes. Then it may be necessary to exclude some of the more specific ones. But again, if a code in this exclusion list is again an anchor to another set of codes, it may be necessary again, to include some of those. At this point the recursion restarts. (It must be noted that this kind of definition only works for hierarchic codesystems.)
An intensional definition is providing a dedicated list of codes (as a triplet). This can also be called an explicit list.
An extensional definition is done by providing information that allows for creating a dedicated list of codes (as a triplet). This is an implicit list of codes.
Note: Intensional and extensional forms can be used together in a single value set definition.
In V3, the notion of required, permitted, and excluded was introduced. In principle, this is a connotation or shutcut for defining multiple value sets at once: By marking each value with one of those codes, perhaps in a different way in different use cases, is just a different representation form of grouping values together. Using parameters for the use case in combination with attributes to the values as described below would result in the same.
If the intent of a value set definition is not specified exactly enough, a modification becomes necessary. In principle, this concerns the logical definition itself in case the description is not exactly representing this intend. Or it can be the explicit definition by defining how this definition should be filled with codes.
As an example, a ZIP code may be necessary for a certain postal area. If the area is not specified exactly enough, e.g. the state of New York instead of the city, the logical definition has to be adapted. In case the correct area is named correctly with “New York City”, but that compose statement to select the appropriate subset of codes is wrong (definition of a filter) then it is a simple modification.

Do we need to separate both?
How to expand a list?
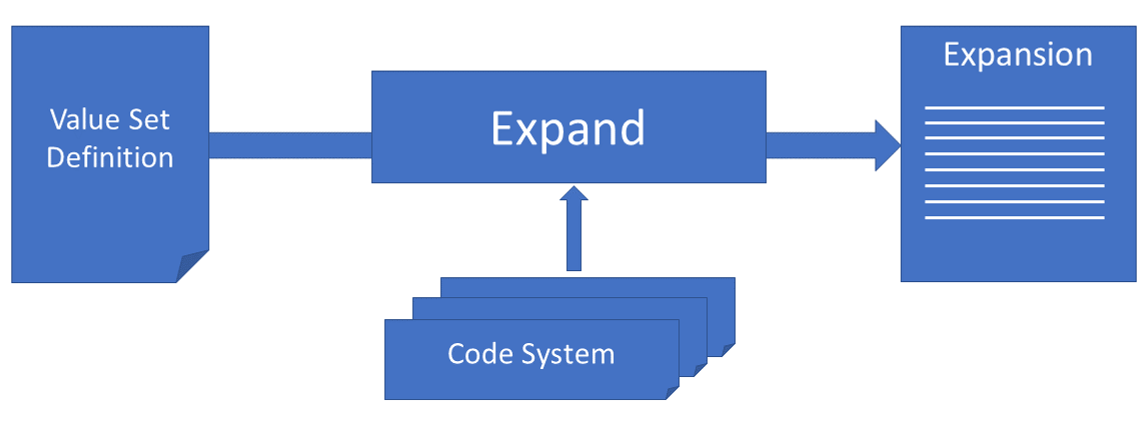
The details of a value set definition as listed above is used to generate - expand - to a dedicated list of codes, the value set expansion. How this is done in detail is out of scope here. What matters is the primary set of data that is of interest:
In FHIR, the list of parameters is part of the expansion. Therefore, it informs about the parameters that have been used to generate the expansion. That raises the question how value sets are maintained (in FHIR)? How many instances are needed to represent a specific value set, perhaps with different expansions.
A value set definition should contain the necessary information to generate an expansion! But perhaps this belongs to the next two sections?!
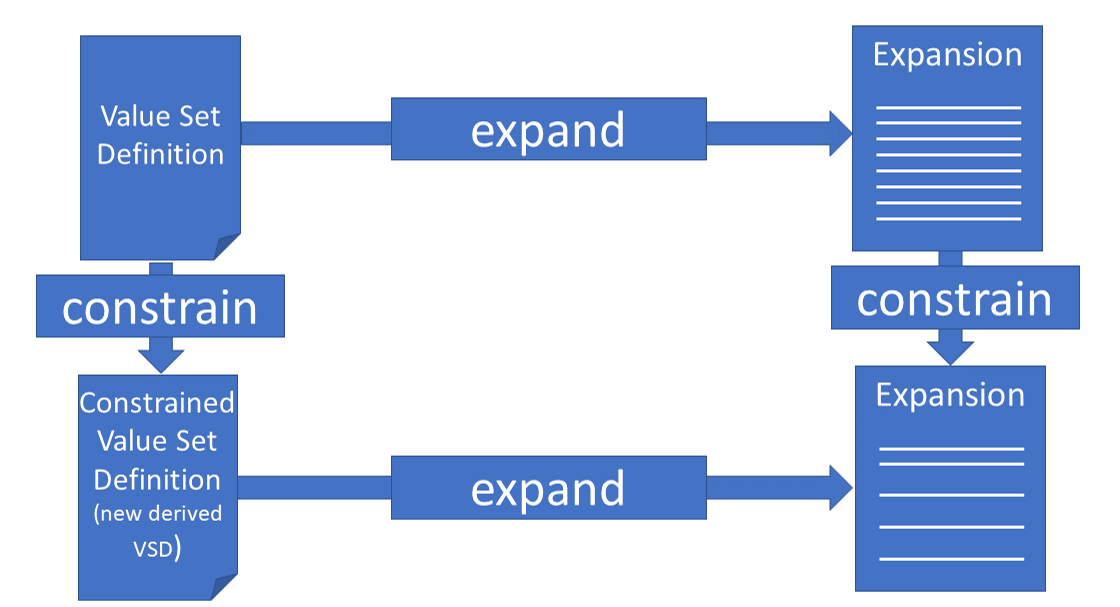
It makes sense to reuse a value set definition for slightly different purposes. For example, a value set for all lab observations may be used to generate a subset for blood examinations just by only applying a filter. On the one hand side, an appropriate parameterization must be made visible. On the other hand, using parameters to create a subset is accompanied by changing the semantics. In the aforementioned example, a subset for blood examinations is distinct from a value set for all lab values. It is indeed a pragmatically way to manage a set of value sets, but in effect it semantically defines a new value set definition - just in a comprised way. In principle, this is a shortcut for a hierarchy of different value set definitions, each parameter value allowing for its own value set. (Consequently, if several parameters are provided, this will result in a combinatoric explosion.) => Constraining value sets!
However, it may help to specify in which ways a derived value set definition relates to the original one.
Beside a simple triplet for codes, an expansion may include more details - for the developers sake. However, of course it is convenient to structure the value set for direct display - without any further interaction. Nevertheless, this has nothing to do with “pure” value sets according to the original intend:
It makes sense to provide some parameters so that different complex expansions can be generated. For example, to add language-specific designations, e.g. in German or Dutch.
The addition of further details should not be mixed up with profiling or constraining a value set further. As an example, a subset of ZIP codes for a specific federal state is not solved by generating an expansion with certain parameters. This must be done by a separate value set definition.
For example, a general value set for postal routing codes (ZIP codes) will end up in a total list of ZIP codes for a specific country. Therefore, the value set definition may be defined as “postal routing codes for USA”.
Reducing it to “postal routing codes for Alabama” as a subset is not done by filtering the expansion, it must (and can) be done in different ways:
In this case, the value set definition is constrained by adding more requirements.

From this constrained definition a new value set is generated by expanding it accordingly.
The other way to constrain a value set is by adding constraints, e.g. parameters or filter, to the result set.

Do we reach a situation where the rectangle is closed?
A value set needs a definition, i.e. a statement that explains what this value set is good for:
The details about coded information must be represented somehow. HL7 FHIR and v2.x are following different paths here:
In HL7 v2.x, there is subdivision into coding that is predefined by HL7. This kind of vocabulary is called HL7-defined and requires the use of vocabulary that is defined by HL7. From a binding perspective, additional codes are allowed if an equivalent is not provided. The other option is user-defined which means that the given codes are just provided as an example. One can use this vocabulary, but is free to define something else.
On the other hand, if the codesystem is implied, i.e. it is not necessary to mention it, the information can be reduced to the code alone: ID and IS. But if more details are required, CNE and CWE can be used. Structurally they are identical, so that beside the original text a triplet of details are conveyed. The use of those differs in that CNE is used for HL7-defined vocabulary, whereas CWE is to be bound to user-defined vocabulary. That separates the use to where the binding appears.
In HL7 FHIR coded information is organized into a hierarchy. It starts with the simple code which is in principle equivalent to ID/IS. On the next level, Coding is providing the details about the codesystem itself. CodeableConcept in the end is then only adding more text.
Codesystems are the central access point to vocabulary. In principal, they can represented like this:
However, this high-level diagram must be specialized depending on the type of the codesystem. If it is a classification the concept is identified by a code, whereas in a terminology there may be a distinction.
TODO: This must be described in more detail, most probably on a separate page.
History has shown, that eleminating/deleting codes from a codesystem results in a new codesystem. Therefore, instead codes should be deactivated by deprecating them. For that purpose, a status code must be maintained.
A good question is what should be done, if a deprecated code/concept becomes necessary ie. valid again? Because codes are unique, there is no choice to make them active again. When using concepts, a new concept with an equivalent semantics can be introduced. However, good practice requires not to have different concepts with exactly the same semantics. Having said that, it makes sense to reactive concepts as well.
FHIR has introduced the notion of a namespace. In principle, this has a technical background, and is distinct from a concept domain. A namespace should support in selecting appropriate “versions” of a codesystem, if the semantic name and therefore the identifier changes.
This is typically true for classifications like ICD: ICD has according to its name different versions. But in reality that are independent codesystems, with different identifiers. (If in ICD a code is added, by its nature this results in a new codesystem.) The namespace is intended to bind those completely independent codesystems together.
There are different ways how value sets can be provided to a user:
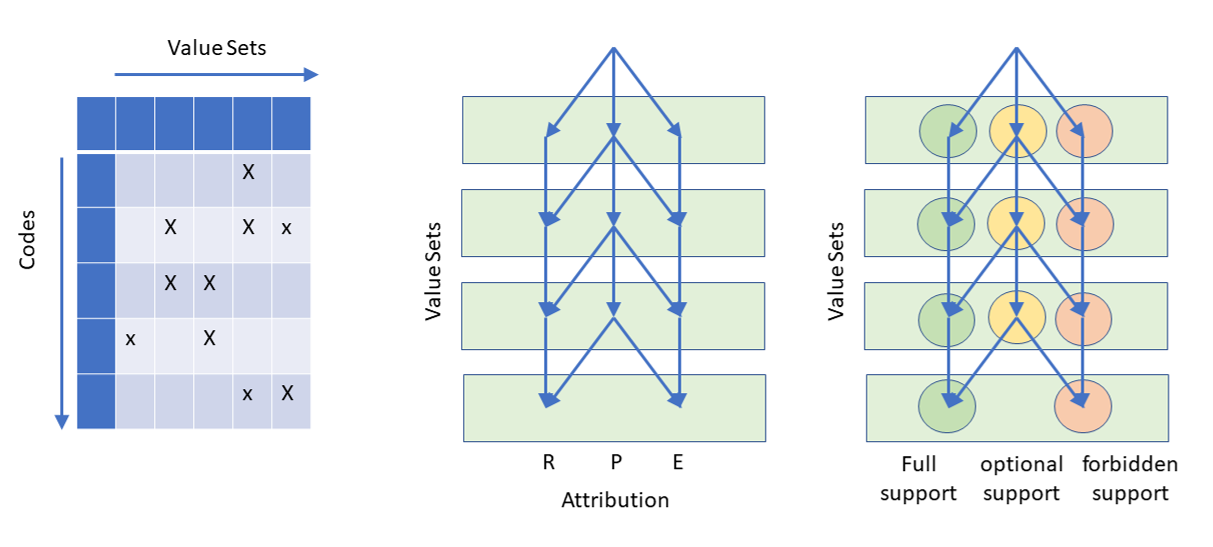
In principle, it always end in a mathematical set operation. There are some means necessary that specify the list of codes that must be supported, and whether this suppport is in total or for a subset only.
A FHIR ValueSet expansion allows working with offsets. This seems to be another convenience function when querying large value set expansions. Parhaps that should be replaced by an explicit paging mechanism and be part of the interface.
First, the terms null-flavor and data absent reason are in principle the same: They document that some information is not available. However, the first is used with HL7 V3, the latter with FHIR. With HL7 V3, this is built in natively, i.e. can be used for every element or attribute - whenever needed. The original intent was to have it available without discussing it again and again. With FHIR, that is deferred to extensions which are also possible everywhere. If someone is conformant to FHIR, an application should accept the extensions without claiming an error. Furthermore, although there are some kind of “standard” extensions, it is up to an implementation guide writer to reuse that or not. So it depends how missing data is handled.
However, good coding practice is to not define codes for this kind of information. Instead, a combined value set has to be defined that uses (includes) codes from this codesystem either implicitly or explicitly.
The aforementioned drawing demonstrates it in principle. However, in details the value set definition has to specify whether and how codes from those two (or more) codesystems have to be selected. But this is explained somewhere else on this page.
How shall a binding be declared if for a coded information item only a single code is allowed?
Option 1 is simpler, but Option 2 does not introduce a new mechanism. For a user, both options may be rendered/displayed the same way. So these two options differ only how it is stored internally.
How to specify when a binding of a coded item shall occur to a specific codesystem only? This is for v2.x the case for HL7-defined tables. Most probably this must be done by defining an appropriate value set that contains this binding already.
Are all value sets persisted in some way? Or is it sufficient to persist an overarching, more generic value set? That opens the discussion for mapping logical concepts (here value set something) into persisted technical items.
TODO
When does it make sense to define and associate a value set to a coded information? Since a standard should be generally applicable only functional - structural - value sets resp. codesystems shall be introduced. In v2, some example “tables” with an example binding are created to introduce the notion behind the element. Consequently, in a derived profile this “table” must be replaced with a proper value set being bound to a real codesystem. Therefore, most of the “tables in v2” are just placeholders for concept domains. Ideally, this specialisation and binding follows the guideline explained earlier.
Realize an overarching domain information model for vocabulary that fulfills the aforementioned details and assembles them into a single model, so that none of the details are lost!
The appropriate details are explained on the next page: problems with terminology.
Of course there are different ways when it comes to realization. Normally, different options are possible. This topic is discussed on a separate page.
Another discussion is about what should be part of the base standard? In which way shall vocabulary be included in the base standard/famework? is it really necessary?
In v2.x the inclusion of vocabulary is done in form of tables, where the table type distinguishes between coded information that is necessary so that the standard works (so-called HL7 tables), and coded information that should be adjusted by the user. Quite often, the latter is done with values that are reasonable and more or less complete for use. Administrative gender or marital status are good examples thereof. However, this separation already denotes a categorization into coded information that is necessary for the framework, and details that should belong into implementation guides. This recognization lead to the v2+ initiative describes here, that tries to introduce this new notion.
Nevertheless, even this distinction requires that a value set is placed as the binding element between codesystems and coded elements.
That refers to the fact, that the machinery is to be provided, and the use of that has to follow the rules and guidance described on this page.