v2+ Details
0.3.2 - Working Draft to present the concept ideas (FO)
v2+ Details
0.3.2 - Working Draft to present the concept ideas (FO)
v2+ Details - Local Development build (v0.3.2). See the Directory of published versions
v2+ is the successor of v2.x. But it does not specify a new set of messages, instead it is written in a new way, and therefor specifies exactly the same. Only the technical terminology is new - or at least different then before. Another main goal is to make it easier to understand the specs by those who are coming from or familiar with other standards, esp. FHIR.
v2.x makes use of terms that after many years are still a reason for (endless) discussions. The conformance constructs being used to specify the details will be replaced so that the understanding is easier and less errorprone.
For a v2-based interface there will be no change!!
Changing the base paradigms of/for v2.x into something new touches 4 different dimensions. Given the vision of HL7 and the way forward, there is currently only one chance to change something. What is not changed now, will stay the same forever:
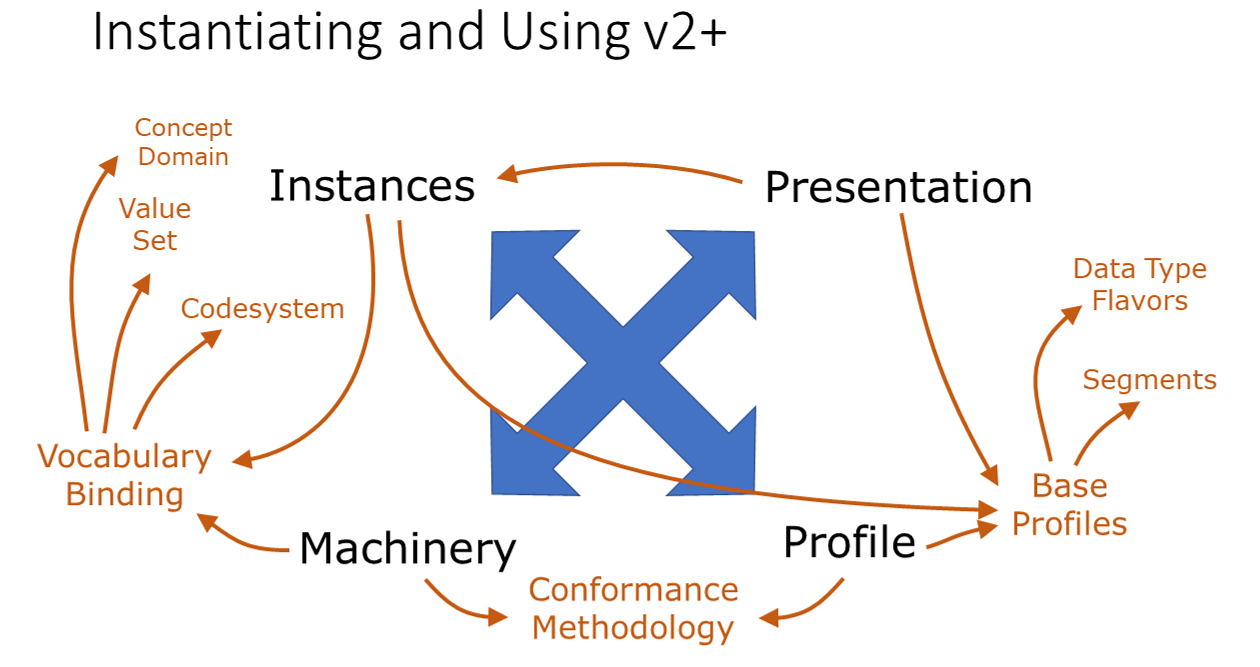
That touches:
Beside a rough listing following, it will be explained later in more details.
One of the primary questions is what should belong to the base standard, and what should belong into a kind of profile? FHIR has answered this question by making everything optional, respectively to be specified within an implementation guide. In v2.x quite a lot of elements are made mandatory/required that are a cause for discussion. This practice comes from the very beginning, where we all had a very rough and inconcise idea about data exchange and the way specifications are written. A good example is the name of the patient in PID-5. In the early days of v2, in 198x and 199x, it has been necessary to convey the name of the patient in every message, because v2 has been used in inhouse environments only. Later on, v2 was a good means for other scenarios like vaccination reporting to health authorities as well. Also, using v2 for registries and/or research raised the problem that the name of the patient may be a problem. It would be easier being able to send a PID instance without a name. Instead, complex alternatives, including the incorrect use of doubble-quotes, were established.
The same is true for quite a lot of the vocabulary. Many tables must be updated for real use - “user-defined tables” - or are just providing some sample values.
All that is a good argument to rethink, what should be part of the base standard, or core framework, and what should be migrated/moved/transitioned to some kind of “most global core set of profiles”!? Introducing that, what is known as v2.x would become this set of profiles, leaving all requirements in place.
What should be part of the standard with regard to:
In which way is the contents presented to implementers/developers? That is independent from how the standard is maintained internally. Of course, this is related to the instances and to the set of base profiles as mentioned before. However, on HL7-EU refactored on can get an idea of how it could look like.
The editing of the standard is described on a separate page.
The “old” technical terminology for v2.x is in use for about 30 years now. That includes the general machinery of dealing with vocabulary and profiles by adding constraints. That will in principle not change.
But because of the long-lasting discussion about the meaning for some of those conformance constructs (like “RE” = “required, but may be empty”) a simplification and harmonization with other standards would be helpful. As introduced in the background page the foundational requiremements are the same for all data exchange standards, but also proprietary definitions from individual stakeholders.
So, to help in aligning with other standards the constraint machinery should be based on a different set of procoordinated technical concepts, that are more inline with more modern standards like FHIR.
That affects
Profiling is part of v2.x for many years. It provides the foundation for what is currently seen in and used with FHIR. Therefore, it will remain in v2+ as well. But as mentioned earlier, it should be discussed, what should be within a profile, and what is part of the core framework.
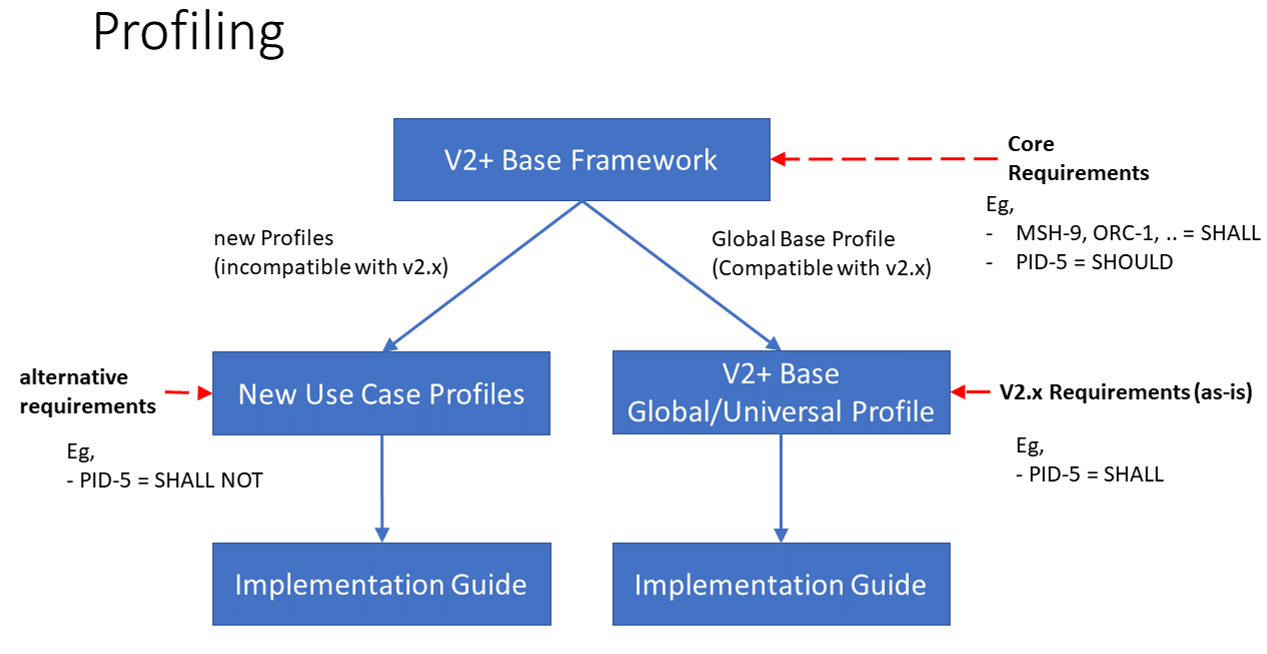
(It would be beneficial to also provide generic message structures, like ADT, that are profiled for certain use, e.g. transfer or discharge. Unfortunately, minor variations in the base message structures prevents from doing that.)
The hierarchy shown in the previous drawing would allow for easier creation of new use cases like research etc.
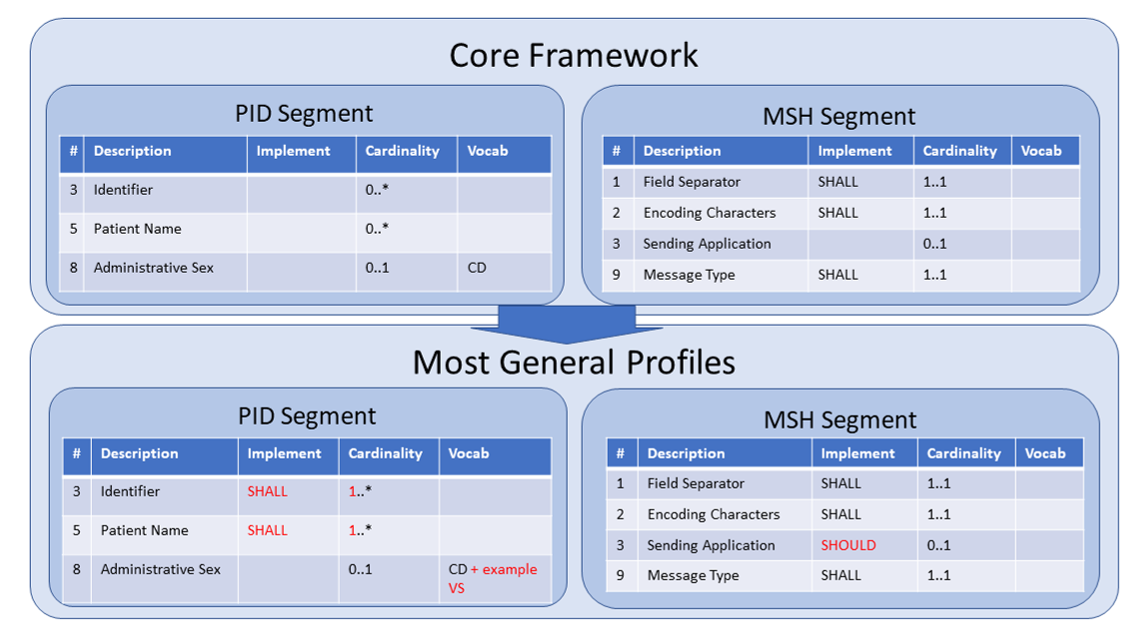
v2.x can be converted/rendered into different representation forms. This is demonstrated currently on Hl7-EU refactored. The following drawing demonstrates the rules that are applied to render an alternative representation with a core framework and a most-general global profile set aside:
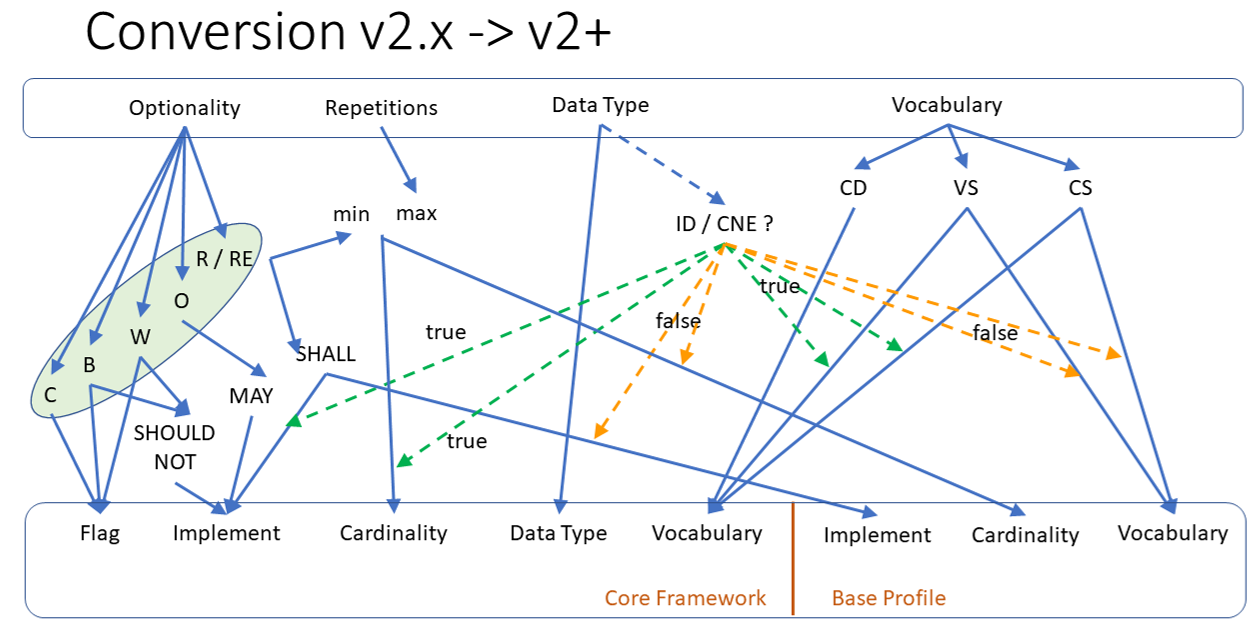
As listed following, the old v2.x conformance constructs will be replaced by the new v2+ constructs. Most of the translation is pretty simple. Given that in v2+ only a few items will remain mandatory i.e. implement=SHALL), the criteria is given by coded elements that have HL7-defined tables that operates as structural attributes which are necessary to make the standard work. (For example, using order control codes in the ORC segment.) For all others, only some guidance (implement=SHOULD) will remain.
TODO: this transition requires verification!
v2.x uses some “old-fashioned” constructs that are not always self-explaining: optionality/usage and repetitions. The way they will be replaced is explained next.
A paradigm for refactoring v2.x is to use the same constructs from the very beginning, i.e. the definition of the standard itself. In v2.x these constructs are named differently in the base standard and derived profiels, i.e. the conformance methodology.
The “optionality” respectively “usage” flag with previous codes of “R”, “RE”, “O”, “B”, “W” and “X” are to be replaced by a new concept, that is aligned with the foundational aspect as pointing to the architecture of a system as explained on background.
| implement | comment | core framework |
|---|---|---|
| SHALL | implementation/support is required | only for structural attributes |
| SHOULD | implementation/support is recommended | an indication of good practice derived from base profile |
| MAY (NOT) | implementation/support depends on the implementor/vendor | not indicated (default) |
| SHOULD NOT | implementation/support is not recommended, but allowed | taken from outdated elements in v2.x (backward, withdrawn) |
| SHALL NOT | implementation/support is forbidden |
Originally, it was thought about to use a simple yes/no flag, like the must-support flag in FHIR. Unfortunately, this is not sufficient if old concepts like “B” or “W” should be maintained and indicated somehow/appropriately. So, this can be achieved best by using the indication of “SHOULD NOT” for “implement” in combination with a flag like “B” or “W” that indicates the why for this recommendation.
The constraining mechanism should work as follows:
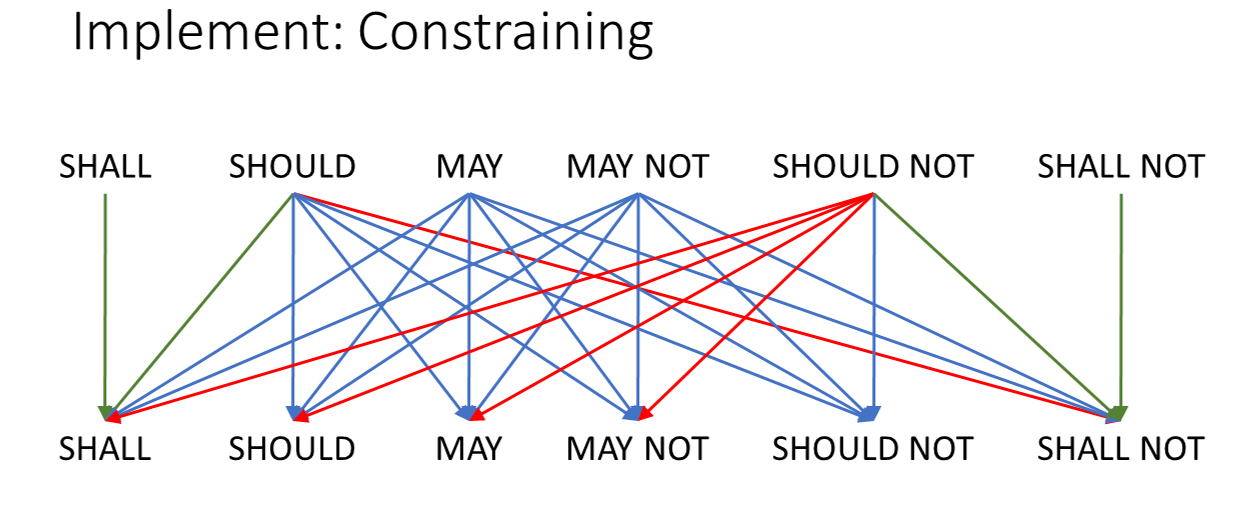
The blue arrows indicate the normal way to constrain this construct. The green arrows indicate the recommended or enforced constraints. The red arrows indicate constrains that are allowed, but discouraged.
This section should talk about what is necessary to migrate from v2.x to v2+, i.e. what kind of changes are necessary. That should also help to understand that both representation forms are identical from what it describes/specify. (They are like different languages making the same statements.)
The “old” view with tables must be replaced with more modern concepts:
The v2 tables project has revealed the individual concepts behind all “tables in v2.x”: In some cases they represent codesystems, and/or value sets, but in all concept domains.
One construct has to indicate whether a specific item must be supported in a somehow meaningful way. In v2.x this construct is called optionality (in base standard) or usage (profile) depending where it occurs.
In addition, this conformance construct is a precoordination of the new “implement” flag and “minimum cardinality” so that the translation can be derived as is shown in the following table:
| optionality/usage | -> | implement | min cardinality | comment |
|---|---|---|---|---|
| R (required) | SHALL | 1 | ||
| RE (required but may be emtpy) | SHALL | 0 | item must be provided/handled if available, but it can be absent (only used in profiles due to late introduction into the conformance methodology) | |
| O (optional) | MAY | 0 | it is the implementers choice to deal with it | |
| B (backwards) | SHOULD NOT | |||
| W (withdrawn) | SHOULD NOT | it is still allowed to use this element, so “SHALL NOT” is not correct |
It should be noted, that only partially a derivation is possible.
Beside these basic constructs that can be translated into the new “implement” flag some more are available that deal with conditions:
| optionality/usage | -> | implement | comment |
|---|---|---|---|
| C | translates to C(R/X) | ||
| CE | translates to C(RE/X) | ||
| C(a/b) | individual specification for true/false statement |
Conditions are explained in more details on a separate page:
It is easier to translate repetitions into cardinality, although it is unclear whether the repetition of “1” equals a maximum cardinality of “2” because the information possibly does not count!?
In other words, repetition will be translated into maximum cardinality.
Like in FHIR, additional flags are used to indicate further details. They can placed into three groups:
| Group | Value | Description |
|---|---|---|
| Condition | ||
| C | A hint to a condition. | |
| Compatibility | ||
| B | for backward compatibility, in combination with “SHOULD NOT” | |
| W | for withdrawn elements, in combination with “SHOULD NOT” | |
| Truncation | ||
| # | allowed | |
| = | not allowed |
See: vocabulary
The different HL7 product lines have different terminology to indicate the reason why certain data is not provided.
In HL7 V3 this is called null-flavor and is a built-in feature: Every information item, no matter of the data type, can convey information why this data for a specific element (or attribute) is not available.
With FHIR this is called data-absent-reason and belongs to an extension that can be used in every resource, attribute or data type. The underlying terminology (code system) slightly varies, but in essence pursues and fulfills the same purpose. (The difference is that in V3 this is foundational and part of the architecture, in FHIR it can (but need not) be used in this or a different way. Therefore, the way it is used in FHIR depends on the individual implementation guide and is therefore matter to change.)
v2.x, and also v2+ does not have a null-value, although this term occurs. Null-values are only available in tables, but in different ways, any also only in a few.
The two double-quotes should not be mixed with null-values. The quotes are a requirement for the receiver to delete the values he currently maintains. In a many-one relationship between sender and receiver that can result in unforseeable results.
How to create and maintain message structures? Like in v2.x, in v2+ a message structure is comprised of either other message structures or specific segments that are placed in a specific position with an indication for implementation, and appropriate cardinality.
What is relevant for data elements and how do they relate to segments?
In the v2 database, data structures are used on top of data types to help with maintaining subtle differences in the early versions of v2.x (v2.1 and v2.2): At the very beginning, the data type CM has been generally used to introduce components, but without separating them. In later versions, CM was replaced with individual data types so that a distinction is not necessary any more - except for database maintenance of all versions.
For v2+ a restructuring may occur:
v2 data types are the means to introduce further structures on the field level. However, the datatypes solve different purposes that should be separated:
In the future, data structures should aggregate components, that logically belong together, whereas data types are used to manage a single item, even if different aspects (components) are necessary.
The basic idea behind the following diagram is the separation into (complex/logical) data structures and more technically oriented data types. A data element should (high-level) only point to either or, but not both.
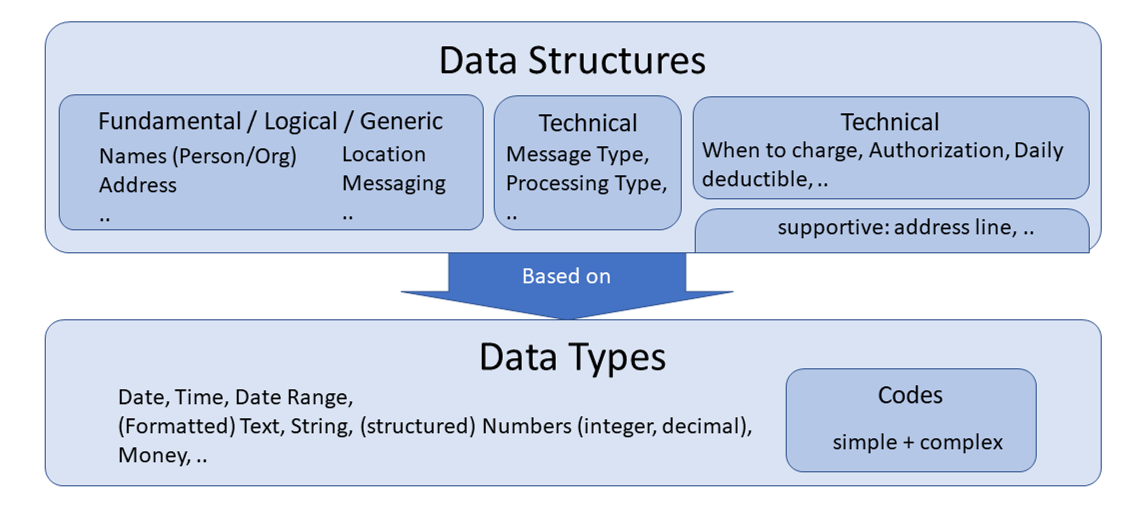
To integrate with vocabulary:
The originally called component table as originally introduced in v2.4 fulfills two different purposes:
Therefore, the currently defined data types in v2 can be sorted following. (Outdated data types are left out):
| name | purpose | components | type | comment |
|---|---|---|---|---|
| XAD | address | street, ZIP, city, country, … | structure | |
| XPN | person name | given, family, spouse, prefix, suffix | structure | unclear use in certain countries |
| XON | organization name | .. | structure | |
| XTN | telecommunication address | phone number, email, type, use | structure | |
| CX | .. | .. | structure | |
| TS | timestamp | date+time + precision | type | |
| DR | date range | start and end date | type | |
| DT | date | date | type | |
| TM | time | time + precision | type | |
| ID | identification (HL7) | code | type | |
| IS | identification (user) | code | type | |
| CNE | coded information (HL7) | code, codesystem, etc. | type | |
| CWE | coded information (user) | code, codesystem, etc. | type |
This way, complex components can be called data structures, that are using data types, which are component-based as well, to comprise the relevant details.
v2+ can be defined by instantiating the following constructs:
They will be explained separately.